(I originally posted this on my MSDN blog.)
About six months ago I published some example code for enrolling for smart card certificates across domains. Of course, once you’re able to enroll for a smart card certificate across domains, at some point you’ll also need to renew that certificate across domains or remotely via the internet. Renewing within a domain is trivial – you just set up the template for autoenrollment and you’re good to go. Doing the same thing without domain support is a difficult and poorly-documented exercise, so I’m sharing my hard-won knowledge with you.
My scenario:
- Users are located externally and connect via the public internet to secure web servers in my domain.
- Users use smart cards to authenticate to the web server.
- Users need to renew their smart card certificates periodically.
Here’s some guidance on how to do it.
The Disclaimer
As stated before, I’m not a smartcard, certificate, or security expert. This code seems to work for me but may be wrong in some unknown aspect. Corrections are welcome!
The Concept
The basic idea goes like this:
- The client builds a CMC renewal request for the certificate.
- The client adds the certificate template OID to the CMC request so that the server will know which template to use.
- The client gets a string representation of the CMC request and sends it across the network to the server via an authenticated SSL connection (client certificate is required).
- The server impersonates the user, submits the request to the CA server, and returns the response to the client.
- The client installs the response and deletes the old certificate.
The Code
This code uses the new-ish Certificate Enrollment API (certenroll) that’s available only on Vista+ and Windows Server 2008+. It won’t run on XP or Server 2003. I’m not going to post a complete, working program here since it’s fairly bulky with other concerns. I’ll just cover the key parts that deal with the renewal process itself, without a lot of error handling and other things. Hopefully I haven’t excluded anything important!
Renewal Processor
The first part is the renewal processor class that drives the high-level renewal workflow of creating a request, sending it to the server, installing the response, and rolling back the request if anything goes wrong. The IRenewalService interface handles all the magic of talking to the server which is a topic for another time.
public class RenewalProcessor : IRenewalProcessor
{
ICertificateRenewalRequestFactory _requestFactory;
IRenewalService _renewalService;
public RenewalProcessor(ICertificateRenewalRequestFactory requestFactory, IRenewalService renewalService)
{
_requestFactory = requestFactory;
_renewalService = renewalService;
}
public void Renew(ICertificate certificate)
{
ICertificateRenewalRequest request = null;
ICertificateRenewalResponse response = null;
try
{
request = _requestFactory.Create(certificate);
response = _renewalService.Enroll(request);
InstallResponse(certificate, request, response);
}
catch
{
if (HasOutstandingRequest(request, response))
{
request.Cancel();
}
throw;
}
}
private bool HasOutstandingRequest(ICertificateRenewalRequest request, ICertificateRenewalResponse response)
{
return request != null && (response == null || (response != null && !response.IsInstalled));
}
private void InstallResponse(ICertificate certificate, ICertificateRenewalResponse response)
{
response.Install();
certificate.Delete();
}
}
Certificate Facade
The second part is a facade that helps me manage the certificates. Some facilities are provided by .Net and other facilities are provided by certenroll, so this facade glues them together into a cohesive entity for me.
public class Certificate : ICertificate
{
public Certificate(X509Certificate2 certificateToWrap)
{
this.X509Certificate = certificateToWrap;
}
public string ToBase64EncodedString()
{
byte[] rawBytes = this.X509Certificate.GetRawCertData();
return Convert.ToBase64String(rawBytes);
}
public string TemplateOid
{
get
{
var managedTemplateExtension = (from X509Extension e in this.X509Certificate.Extensions
where e.Oid.Value == “1.3.6.1.4.1.311.21.7”
select e).First();
string base64EncodedExtension = Convert.ToBase64String(managedTemplateExtension.RawData);
IX509ExtensionTemplate extensionTemplate = new CX509ExtensionTemplate();
extensionTemplate.InitializeDecode(EncodingType.XCN_CRYPT_STRING_BASE64, base64EncodedExtension);
return extensionTemplate.TemplateOid.Value;
}
}
public X509Certificate2 X509Certificate { get; private set; }
public void Delete()
{
X509Store store = new X509Store(StoreLocation.CurrentUser);
store.Open(OpenFlags.ReadWrite);
store.Remove(this.X509Certificate);
this.PrivateKey.Delete();
}
private IX509PrivateKey PrivateKey
{
get
{
RSACryptoServiceProvider managedPrivateKey = (RSACryptoServiceProvider)this.X509Certificate.PrivateKey;
IX509PrivateKey key = new CX509PrivateKey();
key.ContainerName = managedPrivateKey.CspKeyContainerInfo.UniqueKeyContainerName;
key.ProviderName = “Microsoft Base Smart Card Crypto Provider”;
key.Open();
return key;
}
}
}
Renewal Request
The third part is the renewal request. This is the class that builds a CMC renewal request for the certificate and knows how to cancel an in-progress request if necessary. Canceling is important because creating a request creates a new key container on the smart card and if you have several aborted attempts without cleaning up you could fill up the card with empty containers and not be able to renew your certificate. The renewal service (not shown) will get the base64-encoded string representation of the request and send it to the server for enrollment.
public class CertificateRenewalRequest : ICertificateRenewalRequest
{
private ICertificate _certificateToRenew;
private IX509PrivateKey _requestPrivateKey;
public CertificateRenewalRequest(ICertificate certificateToRenew)
{
_certificateToRenew = certificateToRenew;
}
public string ToBase64EncodedString()
{
IX509CertificateRequestCmc cmcRequest = CreateCmcRequest();
IX509Enrollment enrollment = CreateEnrollment(cmcRequest);
string base64EncodedRequest = enrollment.CreateRequest(EncodingType.XCN_CRYPT_STRING_BASE64);
CacheRequestPrivateKey(enrollment);
return base64EncodedRequest;
}
public void Cancel()
{
// Canceling the request means we need to delete the private key created by the
// enrollment object if we got that far.
if (_requestPrivateKey != null)
{
_requestPrivateKey.Delete();
}
}
private IX509CertificateRequestCmc CreateCmcRequest()
{
string base64EncodedCertificate = _certificateToRenew.ToBase64EncodedString();
IX509CertificateRequestCmc cmcRequest = new CX509CertificateRequestCmc();
var inheritOptions = X509RequestInheritOptions.InheritNewSimilarKey | X509RequestInheritOptions.InheritRenewalCertificateFlag | X509RequestInheritOptions.InheritSubjectFlag | X509RequestInheritOptions.InheritExtensionsFlag | X509RequestInheritOptions.InheritSubjectAltNameFlag;
cmcRequest.InitializeFromCertificate(X509CertificateEnrollmentContext.ContextUser, true, base64EncodedCertificate, EncodingType.XCN_CRYPT_STRING_BASE64, inheritOptions);
AddTemplateExtensionToRequest(cmcRequest);
return cmcRequest;
}
private IX509Enrollment CreateEnrollment(IX509CertificateRequestCmc cmcRequest)
{
IX509Enrollment enrollment = new CX509Enrollment();
enrollment.InitializeFromRequest(cmcRequest);
return enrollment;
}
private void AddTemplateExtensionToRequest(IX509CertificateRequestCmc cmcRequest)
{
CX509NameValuePair templateOidPair = new CX509NameValuePair();
templateOidPair.Initialize(“CertificateTemplate”, _certificateToRenew.TemplateOid);
cmcRequest.NameValuePairs.Add(templateOidPair);
}
private void CacheRequestPrivateKey(IX509Enrollment enrollment)
{
IX509CertificateRequest innerRequest = enrollment.Request.GetInnerRequest(InnerRequestLevel.LevelInnermost);
_requestPrivateKey = ((IX509CertificateRequestPkcs10)innerRequest).PrivateKey;
}
}
Renewal Response
The renewal response is pretty simple – all it needs to do is install the response to the smart card.
public class CertificateRenewalResponse : ICertificateRenewalResponse
{
private string _base64EncodedResponse;
public CertificateRenewalResponse(string base64EncodedResponse)
{
_base64EncodedResponse = base64EncodedResponse;
IsInstalled = false;
}
public bool IsInstalled { get; private set; }
public void Install()
{
var enrollment = new CX509Enrollment();
enrollment.Initialize(X509CertificateEnrollmentContext.ContextUser);
enrollment.InstallResponse(InstallResponseRestrictionFlags.AllowNone, _base64EncodedResponse, EncodingType.XCN_CRYPT_STRING_BASE64, null);
IsInstalled = true;
}
}
Request Processor
The request processor is the server-side WCF component that receives the renewal request, enrolls it with the CA, and returns the response to the client. It impersonates the user when it does the enrollment and relies on Kerberos delegation to transfer the user’s credentials to the CA.
public class RequestProcessor : IRequestProcessor
{
public string Enroll(string base64EncodedRequest)
{
ICertRequest2 requestService = new CCertRequest();
RequestDisposition disposition = RequestDisposition.CR_DISP_INCOMPLETE;
string configuration = GetCAConfiguration();
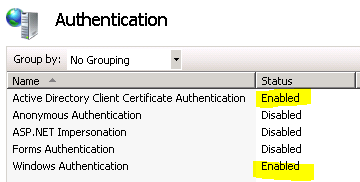
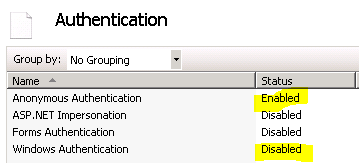
// Submit the cert request in the security context of the caller – this REQUIRES Kerberos delegation to be correctly set up in the domain!
using (ServiceSecurityContext.Current.WindowsIdentity.Impersonate())
{
disposition = (RequestDisposition)requestService.Submit((int)Encoding.CR_IN_BASE64 | (int)Format.CR_IN_CMC, base64EncodedRequest, null, configuration);
}
if (disposition == RequestDisposition.CR_DISP_ISSUED)
{
string base64EncodedCertificate = requestService.GetCertificate((int)Encoding.CR_OUT_BASE64);
return base64EncodedCertificate;
}
else
{
string message = string.Format(CultureInfo.InvariantCulture, “Failed to get a certificate for the request. {0}”, requestService.GetDispositionMessage());
throw new InvalidOperationException(message);
}
}
private string GetCAConfiguration()
{
CCertConfig certificateConfiguration = new CCertConfig();
return certificateConfiguration.GetConfig((int)CertificateConfiguration.CC_DEFAULTCONFIG);
}
private enum RequestDisposition
{
CR_DISP_INCOMPLETE = 0,
CR_DISP_ERROR = 0x1,
CR_DISP_DENIED = 0x2,
CR_DISP_ISSUED = 0x3,
CR_DISP_ISSUED_OUT_OF_BAND = 0x4,
CR_DISP_UNDER_SUBMISSION = 0x5,
CR_DISP_REVOKED = 0x6,
CCP_DISP_INVALID_SERIALNBR = 0x7,
CCP_DISP_CONFIG = 0x8,
CCP_DISP_DB_FAILED = 0x9
}
private enum Encoding
{
CR_IN_BASE64HEADER = 0x0,
CR_IN_BASE64 = 0x1,
CR_IN_BINARY = 0x2,
CR_IN_ENCODEANY = 0xff,
CR_OUT_BASE64HEADER = 0x0,
CR_OUT_BASE64 = 0x1,
CR_OUT_BINARY = 0x2
}
private enum Format
{
CR_IN_FORMATANY = 0x0,
CR_IN_PKCS10 = 0x100,
CR_IN_KEYGEN = 0x200,
CR_IN_PKCS7 = 0x300,
CR_IN_CMC = 0x400
}
private enum CertificateConfiguration
{
CC_DEFAULTCONFIG = 0x0,
CC_UIPICKCONFIG = 0x1,
CC_FIRSTCONFIG = 0x2,
CC_LOCALCONFIG = 0x3,
CC_LOCALACTIVECONFIG = 0x4,
CC_UIPICKCONFIGSKIPLOCALCA = 0x5
}
}
Things To Watch Out For
There are a few tricky issues that I ran across.
WCF and Authenticated SSL
I’m using WCF to communicate between the client and the server. Doing that on top of an authenticated SSL connection is a subject all its own and I hope to post on that separately.
Multiple PIN Prompts
You’ll get multiple prompts for your PIN during the renewal process; either two or three depending on which OS you’re running on and how you organize your calls. The basic problem is that the smart card CSP and the SSL CSP are separate and don’t talk to each other so they can’t reuse a PIN that the other one gathered. At a minimum you’ll get one PIN prompt from SSL and another from the smart card system.
If you’re running on Windows 7, you might even get three prompts if you do the logical thing and first build your request, then connect to the server and send the request, then install the response. This is because in previous versions of Windows each CSP would cache the PIN you entered, but Windows 7 actually converts the PIN to a secure token and caches that. Unfortunately there’s only one global token cache but the CSPs can’t use tokens generated by others, so first the smart card CSP prompts you and caches a token, then SSL prompts you and caches its own token (overwriting the first one), then the smart card system prompts you again (because its cached token is gone).
The solution to minimize the problem is to first do a dummy web service call just to force SSL to set up the connection, then do all the smart card stuff. Once SSL has an active connection you can do multiple web service calls on it without incurring additional PIN prompts.
Impersonation
The idea here is that we first set up the certificate template on the CA to allow users to submit their own renewal requests by signing the request with the old, valid certificate. Then we submit certificate renewal requests with the user’s credentials and the only certificate they can request is a renewal of the one they’ve already got. Because we’re not using an enrollment agent service account here, there’s no risk of an elevation of privileges that would allow a user to get any other certificate.
This plan relies on Kerberos delegation between the web server and the CA server in order for the enrollment to be submitted in the correct context because it’s a double-hop that’s not allowed by default. This is an entire subject in itself and will hopefully be a blog post sometime soon.
However, there are two bugs I ran into while attempting to user Kerberos delegation to the CA. The first bug is that the call to ICertConfig.GetConfig() will fail with a “file not found” error when run while impersonating the user. That makes no sense to me and is probably a Windows bug, but fortunately you can easily call it before you start the impersonation.
The second bug is that certificate enrollment requests will fail on a Windows Server 2003 CA when the user’s credentials are based on a client certificate and delegated from another machine. The call will make it to the CA, but the CA will fail the enrollment with error 0x80070525: “The specified account does not exist.” This is a bug in Windows Server 2003 and was fixed in Windows Server 2008. (Yes, some of our infrastructure is kind of old, but we’re upgrading it now.)